
介绍
学习《kubernetes in action》时做的笔记,书中使用的k8s的版本和目前的版本有差距,但大体概念没有变。转载请注明来自:https://slupro.github.io/
k8s的需求
- 从单一应用到微服务:满足可横向和纵向扩展的需求,聚焦于总的资源池。
- 为开发和部署提供一致的环境:避免了环境差异的问题,比如服务间库的冲突等。
- 持续交付:DevOps和NoOps:一个团队参与开发、部署、运维,是为DevOps,Dev更多地接触生产中的应用,能帮助理解用户需求和问题,更好理解运维团队维护应用所面临的困难。开发者直接部署,不需要系统管理员的帮助,NoOps,系统管理员只关注底层基础设置运转正常。
Docker
Linux namespace: 限制view:文件、进程、网络接口、主机名等。
Linux cgroups:限制进程能用的资源量:CPU、mem、带宽等。
Pod
特点
- pod 是逻辑主机,k8s 管理的最小单位
- pod 上可以运行一个或多个容器,建议一个
- 同一 pod 下的容器使用相同的 network 和 UTS 命名空间,这些容器共享相同的IP和端口空间
- 尽量将容器分散到不同的pod中,除非这些容器间紧耦合,横向扩容时也需要同时扩容
- 一个 pod 不可以跨节点部署
命令
查看pods信息
1
2
kubectl get pods
kubectl get po pod_name -o yaml
使用yaml来创建pod
1
kubectl create -f aaaa.yaml
查看pod中容器的日志
1
2
3
kubectl logs pod_name
// 若pod中有多个容器,使用-c指定容器
kubectl logs pod_name -c docker_container_name
将本地端口映射到pod中的端口
1
2
// 映射本地8888到远程pod的8080端口
kubectl port-forward pod_name 8888:8080
解释pods字段的含义
1
2
kubectl explain pods
kubectl explain pod.spec
使用 labels 来组织 pod
可以给一个pod添加多个标签,label 以 key=value 的方式配置。比如 release=beta 或者 release=prod。
1
2
3
4
5
6
7
8
// 列出 pods 时同时显示标签
kubectl get po --show-labels
// 列出指定的标签内容
kubectl get po -L env,release
// 添加或者修改现有标签,修改需 --overwrite
kubectl label po pod_name env=debug --overwrite
可通过 label 来过滤 pod:包含特定key的标签,包含特定key、value的标签,取非。 可以有:env!=prod, env in (prod,debug), env not in (prod,debug)。
1
2
3
4
5
6
7
8
// 列出包含env的所有pod
kubectl get po -l env
// 列出env=prod且app=service的所有pod
kubectl get po -l env=prod,app=service
// 列出不包含env的所有pod,需要用单引号来避免感叹号被bash shell解释
kubectl get po -l '!env'
事实上,label 可以附加到任何 k8s 对象上,包括节点,方便调度。
用 namespace 来分隔资源
labels 分隔,有可能相互重叠,比如一个对象属于A label,又属于B label。于是有了 namespace分隔,对象不会重叠。
1
2
3
4
5
// 列出集群中的所有ns
kubectl get ns
// 列出指定ns的pod
kubectl get po -n xxx
namespace并不从网络上隔离资源。
删除 pod
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 指定名称
kubectl delete po a-name
// 使用标签
kubectl delete po -l env=debug
// 使用namespace
kubectl delete ns xxx
// 删除当前 ns 的所有pod
kubectl delete po --all
// 删除当前 ns 的(几乎)所有资源,包括pod和service
kubectl delete all --all
谁管理 pod
检查pod是否正常工作 livenessProbe
livenessProbe三种检测方式:
- HTTP GET,检查状态码
- TCP是否能建立连接
- Exec在容器内运行命令,并检查退出状态
1
2
3
4
5
// 容器崩溃重启,查看前一个容器的日志
kubectl logs mypod --previous
// 查看容器重启的原因
kubectl describe po mypod
检查pod是否就绪 readinessProbe
如果 pod 中的服务启动较慢,不能马上对外提供服务,则需要用 readinessProbe 来检测 pod 已正常工作,再使用该 pod。 和 livenessProbe 类似,readinessProbe 也有三种检测方式。区别是:
- livenessProbe 如果检测失败,k8s会终止或重启pod。
- readinessProbe 如果检测失败,不会终止或重启pod。service不会将请求转发给该pod。
1
2
3
4
5
6
7
8
9
10
11
12
13
# 用 ls 检查 /var/ready 是否存在,存在返回退出码0。
kind: ReplicationController
spec:
template:
spec:
containers:
- name: test-container
image: docker_image
readinessProbe:
exec:
command:
- ls
- /var/ready
Replication Controller (会被ReplicaSet取代!)
Replication Controller 持续监控来确保运行了指定的 pod,及其数量。主要有3部分:
- label selector
- replica count
- pod template
更改 label selector 和 pod template 会让 RC 已经运行的pod脱离RC的控制,RC 会关注新创建的pod。老的pod继续运行,并不受RC的监控。 删除一个RC时,其管理的pod会被先行删除。可以用 – cascade=false 来保持pod不被关闭。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 显示 RC 的总体情况
kubectl get rc
// 显示 RC 的详情
kubectl describe rc xxxx
// 修改RC模板
kubectl edit rc xxxx
// 水平扩容
kubectl scale rc xxxx --replicas=10
// 删除 RC
kubectl delete rc xxxx --cascade=false
ReplicaSet
ReplicaSet 的行为与 ReplicationController 完全相同,但 pod selector 的能力更强。
配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
1
2
3
4
5
6
// 创建
kubectl create -f aaa.yaml
kubectl get rs
kubectl describe rs
kubectl delete rs kubia
DaemonSet
前面的 RC 和 RS 是在集群中运行特定数量的 pod,如果需要在每个节点上运行,比如日志收集 或 资源监控,则需要用 DaemonSet。nodeSelector 可以让 DaemonSet 部署 pod 到指定的节点。
DaemonSet 目的是运行系统级的服务,所以即使在不可调度的节点,DaemonSet 也可部署 pod。
1
2
3
4
5
6
7
// DaemonSet yaml
kind: DaemonSet
spec:
template:
spec:
nodeSelector:
disk: ssd
1
2
3
4
5
6
7
8
// 查询 DS
kubectl get ds
// 查询节点信息
kubectl get node
// 节点添加disk=ssd标签,需要修改时用参数 --overwrite
kubectl label node aaaaa disk=ssd
Job
Replication Controller, ReplicaSet, DaemonSet 都是保证 pod 一直在运行,如果失败,会重新运行一个 pod。如果需要 pod 只执行一次,那么就可以用 Job。
1
2
3
4
5
kind: Job
spec:
template:
spec:
restartPolicy: OnFailure
1
2
3
4
5
// 查看 job
kubectl get jobs
// 使用 -a 可查看已经退出的job
kubectl get pod -a
Job 可以创建多个 pod 实例,以串行completions或者并行parallelism的方式运行。
1
2
3
4
5
6
7
8
// 顺序运行 5 次
spec:
completions: 5
// 5 个 pod 执行完,最多 2 个可以同时运行
spec:
completions: 5
parallelism: 2
可以设置 activeDeadlineSeconds 来限制 pod 运行的时间,超过此时间了将终止 pod,并标记为失败。spec.backoffLimit,可以配置 Job 在失败前被重试的次数,默认为6。
CronJob
CronJob 类似于 Linux 的 cron,定时执行任务。分钟,小时,每月的第几天,月,星期。
可以通过 startingDeadlineSeconds 来指定最晚不能超过的时间,如果超过,则显示为 Failed。
1
2
3
4
kind: CronJob
spec:
schedule: "0,30 * * * *"
startingDeadlineSeconds: 15
Service
由于 Pod 随时可能会创建或者销毁,所以要和 Pod 内容器通信需要提供方式能让客户端找到 Pod 的IP和端口,service用来解决这个问题。
Service 为一组功能相同的 pod 提供单一不变的接入点。客户端通过IP、端口号和service建立连接,这些连接会被路由到提供该服务的任意一个 pod 上。
Service 的创建
可以用yaml或者 kubectl expose 命令创建service。
如果需要将同一客户端的请求都重定向到后台同一个 pod,需要使用 spec.sessionAffinity: ClientIP,默认该属性为None。
// 所有app=labelname 的pod都属于该service。 kind: Service spec: sessionAffinity: ClientIP ports: - port: 80 targetPort: 8080 selector: app: labelname
服务发现
两种方式:
- 通过环境变量。service 用的 IP地址和端口,会在 pod 的环境变量中保存,podname_SERVICE_HOST 和 podname_SERVICE_PORT。
- 通过DNS。kube-system 命名空间下有个 kube-dns pod,上面运行了DNS,集群中的其它pod都被配置成使用kube-dns当作DNS server(修改了/etc/resolv.conf)。pod是否使用内部的DNS通过 spec.dnsPolicy 来确定。
1
2
3
4
5
// 查询 service,可看到集群内通信用的 cluster-ip
kubectl get svc
// 查询环境变量
kubectl exec xxx env
FQDN 命名规则: backend-service.default.svc.cluster.local
其中,backend-service对应service名称,default对应namespace,svc.cluster.local是可配置的集群域后缀。如果在一个命名空间下,可以直接用 backend-service 来访问。
集群内的 pod 连接集群外的服务(通过IP)
可以利用service的负载均衡和服务发现,让集群中的客户端pod可以像连接内部服务一样连接外部服务。
service 并不直接和 pod 直接相连,Endpoint 资源介于 service 和 pod 之间,Endpoint 资源就是一组IP地址和端口列表。可以单独的创建没有pod的 service ,然后为其创建 Endpoint 资源。
1
2
3
4
5
// 查看service的细节
kubectl describe svc xxxx
// 查看endpoints
kubectl get endpoints
创建service
1
2
3
4
5
6
7
apiVersion: v1
kind: Service
metadata:
name: slutest-service
spec:
ports:
- port: 80
为该service创建endpoint,两者的 metadata.name 必须一样才能关联。
1
2
3
4
5
6
7
8
9
10
apiVersion: v1
kind: Endpoints
metadata:
name: slutest-service
subsets:
- addresses:
- ip: 12.12.12.12
- ip: 22.22.22.33
ports:
- port: 80
集群内的 pod 连接集群外的服务(通过域名)
需要指定 service 的spec.type 为 ExternalName。集群内的pod可以通过域名 ext-svc 访问外部的 api.externalsite.com。
1
2
3
4
5
6
kind: Service
metadata:
name: ext-svc
spec:
type: ExternalName
externalName: api.externalsite.com
集群内的 pod 对外提供服务 (NodePort)
创建一个 NodePort 类型的 service,可以在所有节点上都开放一个相同端口号的端口,任何一个节点接收到传入的连接,都会转发给提供服务的 Pod。
下面的例子中将开放每个集群节点的1234端口,可以访问每个节点的1234端口,或者cluster-ip的80端口,数据包会被转发到service对应pod的8080端口。kubectl get svc 可以查看 CLUSTER-IP。
NodePort 需要打开节点上 1234 端口的防火墙。Load Balancer 方式则不需要修改防火墙配置。
但是,如果只通过一个节点的IP访问集群服务,该节点挂掉时,就无法访问了。所以有了后面的负载均衡方式。
1
2
3
4
5
6
7
8
9
kind: Service
spec:
type: NodePort
ports:
- port: 80
targetPort: 8080
nodePort: 1234
selector:
app: outservice
集群内的 pod 对外提供服务 (Load Balancer)
Load Balancer 拥有自己唯一的可公开访问的IP地址,并将所有连接重定向到服务。LB是NodePort的一个扩展,如果k8s在不支持LB的环境中运行,则该服务仍以NodePort方式运行。
当启用 LB 时,IP地址将在 kubectl get svc 中的 EXTERNAL-IP 存在。
NodePort 需要打开节点上 1234 端口的防火墙。Load Balancer 方式则不需要修改防火墙配置。
1
2
3
kind: Service
spec:
type: LoadBalancer
spec.externalTrafficPolicy: Local 该配置可以让在 NodePort 环境下,接收到请求的节点只将请求转发到本节点内的 pod。 优点是减少了转发到其它节点时的网络hop。 缺点是如果本地没有对应的pod,则连接会挂起,另外如果在LB环境中,由于LB是根据节点做转发,每个节点的pod数不一定相同,可能造成各个 pod 的压力不同。 当使用 NodePort 模式时,由于可能在节点间转发(SNAT),所以后端pod可能无法获取到正确的请求的源IP地址,使用 spec.externalTrafficPolicy: Local 时,由于无跳转,可以获取到正确的源IP地址。
集群内的 pod 对外提供服务(Ingress)
Ingress 功能的支持因不同的 Ingress controller 而定。目前只工作在应用层,支持http/https负载均衡可以根据 url 进行转发,并可提供 session affinity 等功能。
Ingress controller 会将请求直接发送给一个选择的 pod,不会再经过 service 了。
1
2
// 使用下面命令查询 ingress 的IP地址,然后修改客户端DNS,将域名指向该IP地址。
kubectl get ingresses
Ingress 处理HTTPS请求: 需要创建 Secret 资源,将证书和私钥保存到 Secret 上,并将 Secret 附加到 Ingress 上。 请求在客户端和Ingress之间是HTTPS连接,在Ingress和pod之间是HTTP。
1
kubectl create secret tls my-secret --cert=cert_file --key=key_file
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Ingress 将www.test.com映射到后面的service-nodeport,80端口
# rules 和 paths 可以设置多个值,以便细分处理不同域名,不同url的请求。
# 如果不用 TLS,则不需要 TLS 部分
kind: Ingress
spec:
tls:
- hosts:
- www.test.com
secretName: my-secret
rules:
- host: www.test.com
http:
paths:
- path: /foo1
backend:
serviceName: service-nodeport1
servicePort: 80
获取 service 内所有 pod 的 IP(headless)
设置 Service 的 spec.clusterIP: None,则可以创建一个 headless 的服务,该服务不会获得cluster IP,而是会返回该service下所有pod的IP。
1
2
3
kind: Service
spec:
clusterIP: None
Volume 卷
K8s 中的卷是 pod 的一个组成部分,因此和容器一样定义在 pod yaml 中。一个pod中的所有容器都可以使用相同的卷,但必须挂载。卷的生命周期和 pod 的生命周期一样,在pod创建时才会存在。
Volume的类型
- emptyDir: 存储临时数据的空目录
- hostPath: 将目录从节点的文件系统挂载到 pod 中
- gitRepo: checkout git repo的内容来初始化卷
- gcePersistentDisk, awsElasticBlockStore, azureDisk: 用于cloud环境
- configMap, secret, downwardAPI: 将k8s部分资源和集群信息mount到pod
emptyDir
当medium为memory时,k8s将在tmfs文件系统(内存)上创建emptyDir。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 两个容器,共享同一个卷,各自加载到自己的不同目录了。
kind: Pod
spec:
containers:
- image: ubuntu
name: u1
volumeMounts:
- name: mem
mountPath: /tmp1
- image: ubuntu
name: u2
volumeMounts:
- name: mem
mountPath: /tmp2
readOnly: true
volumes:
- name: mem
emptyDir:
medium: Memory
详细示例参考:https://github.com/slupro/kubernetes-config-examples/blob/main/examples/ContainersInOnePod.yaml
1
2
# 进入容器 u2
kubectl exec -it uuu -c u2 -- /bin/bash
gitRepo
gitRepo 先创建pod,k8s 再创建一个空目录(emptyDir),然后clone指定的git仓库到本地,最后再挂载目录,启动容器。
gitRepo 里的内容并不会主动和git仓库同步,只有创建时会同步。可以用于从git上下载网站静态HTML文件,并创建一个包含nginx的容器。
1
2
3
4
5
6
7
8
# gitRepo.directory 指定将repo克隆到卷的位置
spec:
volumes:
- name: volume1
gitRepo:
repository: https://github.com/aaaa.git
revision: master
directory: .
hostPath
- 可让 pod 内的容器访问 node 上的文件或目录。可让同一节点上的多个 pod 访问相同的文件或目录。
- 持久型存储,pod删除时不会删除hostPath。
- 尽量避免使用 hostPath 持久化pod的数据,因为和节点绑定了。除非在需要访问节点数据时,再使用。
其它持久化存储
不同的Cloud基础设施提供了不同的方式,比如 Google Cloud 的 GCE persistent disk,AWS 的 awsElasticBlockStore,Azure的azureFile或者AzureDisk。
1
2
3
4
5
6
7
kind: Pod
spec:
volume:
- name: dbdata
awsElasticBlockStore:
volumeId: myvol
fsType: ext4
1
2
3
4
5
6
7
# 使用 NFS 卷
spec:
volume:
- name: dbdata
nfs:
server: 22.3.3.3
path: /a/path
PersistentVolume and PersistentVolumeClaim
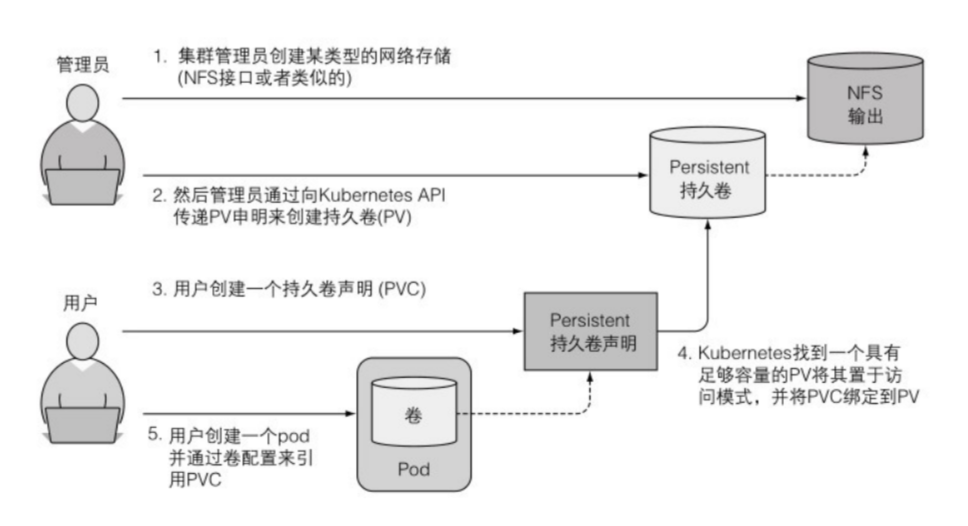
开发人员不需要了解底层实际使用的存储技术,只需要创建pod,指明需要使用的PVC;PVC中包含存储大小和访问模式的需求;运营人员创建PV,来满足PVC的需要。
创建PV和PVC
- 创建持久卷
1
2
3
4
5
6
7
8
9
10
11
12
13
# 容量5G,可以支持单节点和多节点的读写,删除时保留
kind: PersistentVolume
metadata:
name: mysql-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain
hostPath:
path: /temp/k8s
持久卷 PV 不属于 任何namespace,它和节点一样是集群层面的资源。 持久卷声明 PVC 属于 namespace。 PV 和 PVC 状态是Bound时,是绑定的。
1
2
// 查看持久卷
kubectl get pv
- 创建持久卷声明PVC来获取持久卷PV
PVC 和 pod 是相互独立的,这样如果pod被删除并重新创建后,扔可以使用之前的 PVC。
如果要使用手动生成的PV,需要在PVC里设置 spec.storageClassName 为 ““,空字符串。否则PVC会使用默认的storageClassName生成动态PV。
1
2
3
4
5
6
7
8
9
10
11
# 申请1G的存储空间,允许单个客户端访问(读写)
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
spec:
resources:
requests:
storage: 1Gi
accessModes:
- ReadWriteOnce
storageClassName: ""
ACCESS MODES 说明: RWO - ReadWriteOnce,允许单个节点读写 ROX - ReadOnlyMany, 允许多个节点,只读 RWX - ReadWriteMany,允许多个节点读写
1
2
// 查看 pvc 是否已经绑定 pv
kubectl get pvc
- 在 pod 中使用 PVC
1
2
3
4
5
6
7
kind: Pod
spec:
containers:
volumes:
- name: mysql-data
persistentVolumeClaim:
claimName: mysql-pvc
回收 PV
PV 通过配置 persistentVolumeReclaimPolicy 来设置PV的回收方式:
- Retain:PVC被删除后,PV被保留,若要重新使用该PV,需要手动删除并重新创建,手动删除PV前可以处理其中的文件。PVC被删除后,PV状态变为 Released,新创建PVC状态会是Pending,因为老的PV已不可用。
- Recycle:和 Retain 的区别是,Recycle可以被不同的PVC再次申明和使用。
- Delete:PVC被删除时,PV也被删除。
可以修改现有PV的回收策略。
持久卷的动态生成
管理员可以创建一个或多个 StorageClass 对象,用户在 PVC 中引用该 StorageClass,则可自动创建 PV。
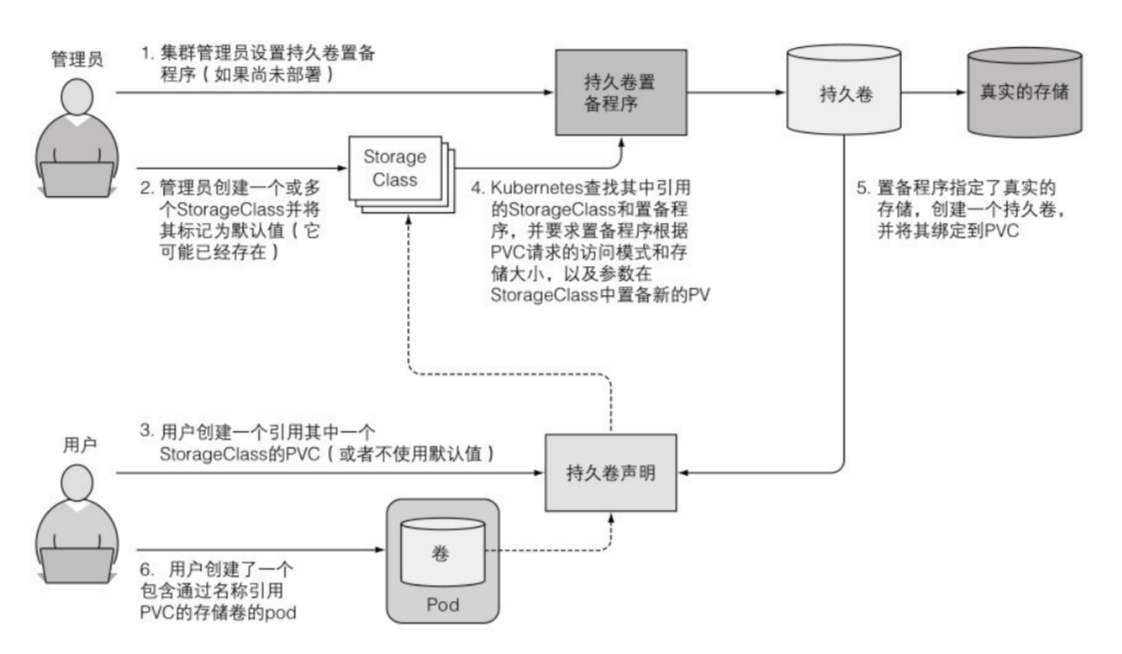
StorageClass
需要使用对应的云提供商的provisoner。
1
2
3
4
5
6
7
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ssddisk
provisioner: k8s.io/minikube-hostpath
parameters:
type: pd-ssd
k8s中会有一个默认的sc,如果pvc没有指明使用哪个StorageClass,则会使用默认SC。
1
2
3
4
5
// 查看StorageClass
kubectl get sc
// 查看默认的standard sc的定义
kubectl get sc standard -o yaml
PVC 从 StorageClass 请求资源
1
2
3
4
5
6
7
8
9
10
kind: PersistentVolumeClaim
metadata:
name: test-pvc
spec:
storageClassName: ssddisk
resources:
requests:
storage: 100Mi
accessModes:
- ReadWriteOnce
配置应用程序:ConfigMap 和 Secret
向容器传递命令行参数
Dockerfile 中的 ENTRYPOINT 和 CMD
- ENTRYPOINT 定义容器启动时,调用的可执行程序。
- CMD 指定传递给 ENTRYPOINT 的参数。
两种运行方式:
- shell (ENTRYPOINT node app.js):用shell调用node app.js,相当于 /bin/sh -c node app.js,主进程(pid1)是shell进程。
- exec (ENTRYPOINT [“node”, “app.js”]):容器启动时直接调用 node app.js,主进程是node。
1
2
3
4
5
FROM ubuntu:latest
RUN apt-get update; apt-get -y install some_app
ADD file1 /bin/file1
ENTRYPOINT ["/bin/file1"]
CMD ["arg1", "arg2"]
启动容器时修改参数
docker 中可以在启动的时候重新覆盖命令行参数:docker run some_image arg3
k8s 可以在配置中,使用 command(=ENTRYPOINT) 和 args(=CMD) 覆盖。容器启动后,不能修改启动参数了。
1
2
3
4
5
6
kind: Pod
spec:
containers:
image: some_image
command: [/bin/file1]
args: ["arg4", "arg5"]
args也可以用下面的方式:
1
2
3
4
5
6
7
# 字符串可以不要双引号,数字需要双引号。
spec:
containers:
args:
- arg6
- arg7
- "33"
为容器配置环境变量
1
2
3
4
5
6
7
kind: Pod
spec:
containers:
image: some_image
env:
- name: some_key
value: some_value
这样只能 hard code 一个值,如果想解耦,可以使用 valueFrom 来从 ConfigMap 中读取数据。
ConfigMap 解耦配置
ConfigMap介绍
- k8s 的 ConfigMap 使用 etcd 保存配置,所以是保存key/value映射。
- 应用程序不用直接读取 ConfigMap,key/value 的信息以环境变量或者卷文件的方式传递给容器,从而更灵活。
- 应用程序也可以通过k8s Rest API读取ConfigMap中的内容。
- 为不同的环境创建不同的ConfigMap(dev,production),pod相同。
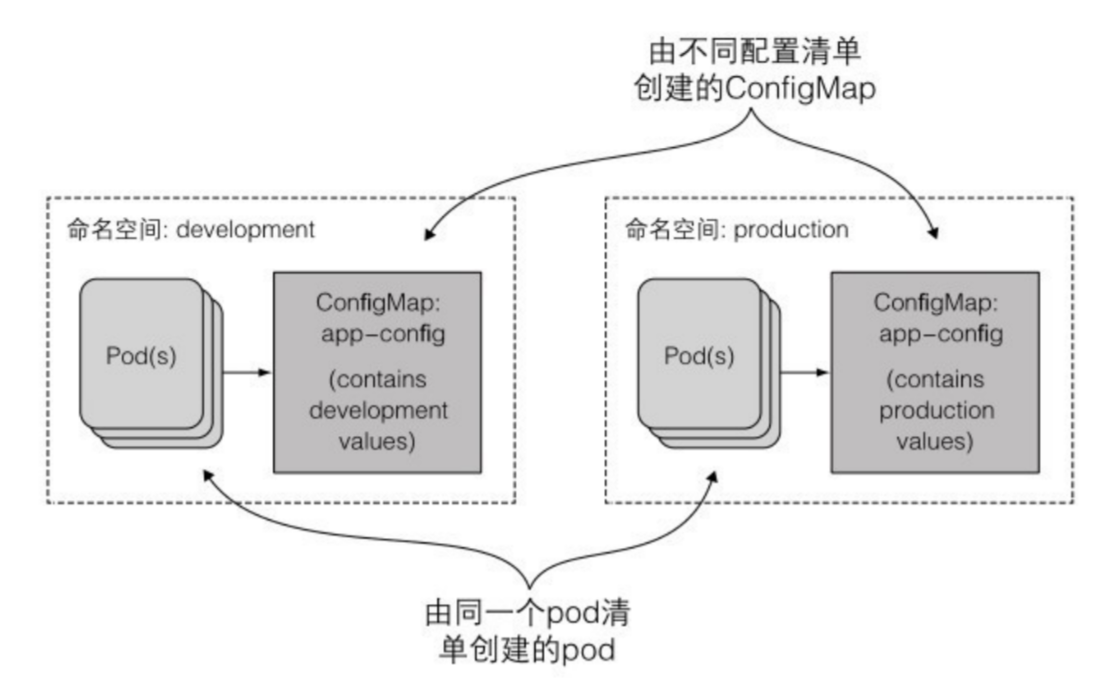
ConfigMap的创建
- 通过命令行 –from-literal 创建。
1
kubectl create configmap mycm --from-literal=key1=value1 --from-literal=key2=value2
- 通过 yaml 文件创建
1
2
3
4
data:
key1: value1
key2: value2
kind: ConfigMap
- 通过文件或目录创建,可以将文件的内容加载到key。没有指定key时,使用文件名作为key。
1
kubectl create configmap mycm --from-file=xxx.conf --from-file=key=somefile --from-file=folder/
1
2
3
# 查看cm内容
kubectl describe cm mycm
kubectl get cm mycm -o yaml
将ConfigMap的内容传递给容器的环境变量
个别变量可以通过 valueFrom 来引用,或者用 envFrom 来引用所有条目作为环境变量。
如果创建pod时,引用的ConfigMap不存在,受影响的容器会启动失败,其它pod中的容器可以正常启动。当CM中的信息补全后,失败的容器会自动启动。也可以设置成CM信息不存在也继续启动容器,设置 configMapKeyRef.optional=true。
当有非法的环境变量key时,该环境变量会被忽略,忽略时不会发出事件通知。比如key中包括-。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 容器xx中将存在环境变量 env-key,值从ConfigMap mycm的key_in_cm中获取。
# 容器xxx中将会有mycm中的所有key:value在环境变量中,key会被添加前缀CONFIG_。prefix是可选的。
kind: Pod
spec:
containers:
- image: xx
env:
- name: env_key
valueFrom:
configMapKeyRef:
name: mycm
key: key_in_cm
- image: xxx
envFrom:
- prefix: CONFIG_
configMapKeyRef:
name: mycm
configMap卷 可以把配置加载成volume
configMap卷 默认会把CM中的每个条目均暴露成一个文件。key为文件名,value为内容。如果需要选择暴露的key,需要使用spec.volumes.configMap.items.key来指定。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
kind:Pod
spec:
containers:
- image: xx
volumeMounts:
- name: vconfig
mountPath: /etc/conf.d
readOnly: true
volumes:
- name: vconfig
configMap:
name: mycm
items:
- key: key_in_cm
path: my.conf
configMap卷加载后,容器镜像中原有目录将被清空。如果不需要清空原有目录,需要使用 spec.containers.volumeMounts.subPath 来指定文件名。 configMap卷中文件的默认权限被设置为644(-rw-r-r–),可以通过 volumes.configMap.defaultMode 来修改文件的权限。 环境变量和启动参数无法在不重启容器的前提下修改,但configMap卷可以不重启容器就修改。
用Secret传递敏感数据
Secret简介
- Secret 与 ConfigMap 类似,也是key/value映射。
- Secret 与 ConfigMap 类似,条目可以通过环境变量传递给容器,可以暴露为volume中的文件,只分发到需要访问的pod上。
- Secret 之会保存在节点的内存中,不会写入物理存储,这样从节点上删除secret就不用擦除磁盘了。
- k8s 1.7开始,etcd会加密保存Secret。
默认Secret token
系统会有一个默认的Secret,并默认会挂载到每个容器中。
1
2
3
4
5
6
// 查看
kubectl describe secrets
kubectl get secrets
// 查看pod中default secret挂载的位置
kubectl describe pod
创建 Secret
1
2
# 将afolder目录下的所有文件以及aaa文件映射到mysec Secret上。文件名为key,内容为value。
kubectl create secret generic mysec --from-file=afolder --from-file=aaa
挂载 Secret 到 Pod
1
2
3
4
5
6
7
8
9
10
11
12
kind: Pod
spec:
containers:
image: xxx
volumeMounts:
- name: vol_name
mountPaht: /etc/cert/
readOnly: true
volumes:
- name: vol_name
secret:
secretName: mysec
也可以通过环境变量暴露:env.valueFrom.secretKeyRef。 Secret也可以保存证书,k8s用来从私有仓库里面获得镜像。需要做两件事:创建包含Docker镜像仓库证书的Secret,在Pod的yaml定义中指定需要使用的Secret(spec.imagePullSecrets)。
Secret 和 ConfigMap 的区别
当以 yaml 格式查看 Secret 时,可以看到其中的value都被 Base64 编码了,所以Secret也可以保存二进制的文件作为value。Secret的value大小限制为1MB。但是 ConfigMap 不能保存二进制的信息。
1
kubectl get secret mysec -o yaml
Deployment
更新pod
两种方式更新:先删pod v1,再创建pod v2。先创建pod v2,再删pod v1。第一种方式会导致服务暂时不可用,第二种方式会需要更多的硬件资源。
先删v1,再创建v2
如果用ReplicationController来管理pod的话,直接更新其中的pod模板。
先创建v2,再删v1
蓝绿部署(blue-green deployment):使用service的标签选择器将流量切换到新pod,正常后再删除旧版本的pod。使用kubectl set selector。
用 ReplicationController 实现自动滚动升级
1
2
3
kind: ReplicationController
metadata:
name: testrc-v1
使用 testrc-v2 滚动替换 v1: kubectl rolling-update testrc-v1 testrc-v2 --image=xxx:v2 --v 6。通过参数 --v 6 来显示替换的详细日志。
已不再使用 rolling-update,因为 kubectl 只是执行滚动升级的客户端,具体执行操作是一步步通过rest发送到K8S API完成,如果升级中网络出错,升级将会中断。
Deployment
Deployment是更高层的资源使用方式,ReplicationController和ReplicaSet更底层。在使用 Deployment 时,pod是由Deployment底层的ReplicaSet创建和管理的。
创建 Deployment
Deployment创建的定义方式和ReplicationController类似,只是 kind 为 Deployment。
1
2
3
4
5
6
7
8
9
# 创建Deployment,--record 会记录历史版本号
kubectl create -f xxx.yaml --record
# 查看
kubectl get deployment
kubectl describe deployment
# Deployment 是使用 ReplicaSet 管理pod
kubectl get replicasets
使用 Deployment 升级
Deployment升级有两种方式:
- RollingUpdate:默认升级策略,会创建新的pod,并逐渐删除旧的pod。底层的ReplicaSet不会被删除,恢复时使用。
- Recreate:一次性删除所有旧pod,再创建新pod,中间会有不可用的时候。
1
2
3
4
5
6
7
8
9
10
11
12
# 修改单个或少量资源属性时,可使用 kubectl patch。
# minReadySeconds 设置滚动升级的速度。
kubectl patch deployment xxx -p '{"spec": {"minReadySeconds": 10}}'
# 将deployment_name的pod模板中的镜像改为image_name:v2。触发滚动升级。
kubectl set image deployment xxx container_name=image_name:v2
# status可以查看升级的详细过程
kubectl rollout status deployment xxx
# 使用pause或resume暂停或恢复滚动升级,用于Canary金丝雀发布
kubectl rollout pause/resume deployment xxx
控制滚动升级速率:maxSurge 和 maxUnavailable 属性。 minReadySeconds,新pod至少运行多久后才视为可用。 默认情况下,超过10min不能完成滚动升级,将被认为失败。可以通过设置progressDeadlineSeconds来设定。
回滚 Deployment 的升级
升级后不应手动删除 ReplicaSet 的信息,这些信息保存着历史版本,以便进行回滚。
手动回滚:
1
2
3
4
5
6
7
8
# 回滚到上一个版本。undo命令可以在滚动升级的过程中执行。
kubectl rollout undo deployment xxx
# 查看升级的历史版本
kubectl rollout history deployment xxx
# 回滚到指定版本
kubectl rollout undo deployment xxx --to-revision=1
StatefulSet
ReplicaSet 和 ReplicationController 创建的新pod和被替换的pod拥有不同的名称、网络标识和状态。为了保证这些信息在新的pod中保持一致,引入了 StatefulSet。
使用 StatefulSet
StatefulSet 缩容的时候一次只操作一个pod,如果有实例不健康,StatefulSet也不会缩容。避免集群中多个节点出问题时丢数据。
由于一个持久卷声明PVC被删除时,对应的持久卷PV也会被删除。但在 StatefulSet 中,即使缩容,也不删PVC,否则删除PV会造成数据丢失。扩容时,StatefulSet新增的pod会使用旧的PVC,也就是会使用之前pod使用的PVC,从而访问相同的数据。
at most one: k8s 保证不会有两个相同标记和绑定相同PVC的pod同时运行。
- 创建StatefulSet的service时,spec.clusterIP 必须是 None,也就是headless service。
- ReplicaSet 会一次创建所有的pod,但 StatefulSet 会在前一个pod Running后再创建下一个pod。这对于需要选举的节点来说,StatefulSet更安全。
- 缩容的时候,会先删除拥有最高索引的pod。
DNS 中的 SRV 记录
可以在DNS中查询 SRV 记录来获得StatefulSet中的其它pod地址。SRV记录返回的顺序是随机的。
1
2
# 列出 SRV 记录
dig SRV pod.default.svc.cluster.local
修改 StatefulSet
kubectl edit statefulset xxx修改StatefulSet时:
- 如果修改了image的地址,k8s并不会更新已经有的pod。
- 如果spec.replicas增加了,会创建新的pod。
节点失效
当一个节点失效(网络掉了、断电等)后,该节点上的 kubelet 无法与 k8s API 通信,所以k8s认为该节点 NotReady(kubectl get node),节点上的pod的状态为 Unknown。该pod的状态在超时(可配)未更新后,k8s将该pod标记为Terminating(虽然该pod还在断线的节点上运行)。由于k8s已无法通知离线的节点来删除该pod,所以可以手动强制删除kubectl delete po xxx --force --grace-period 0。
k8s 架构
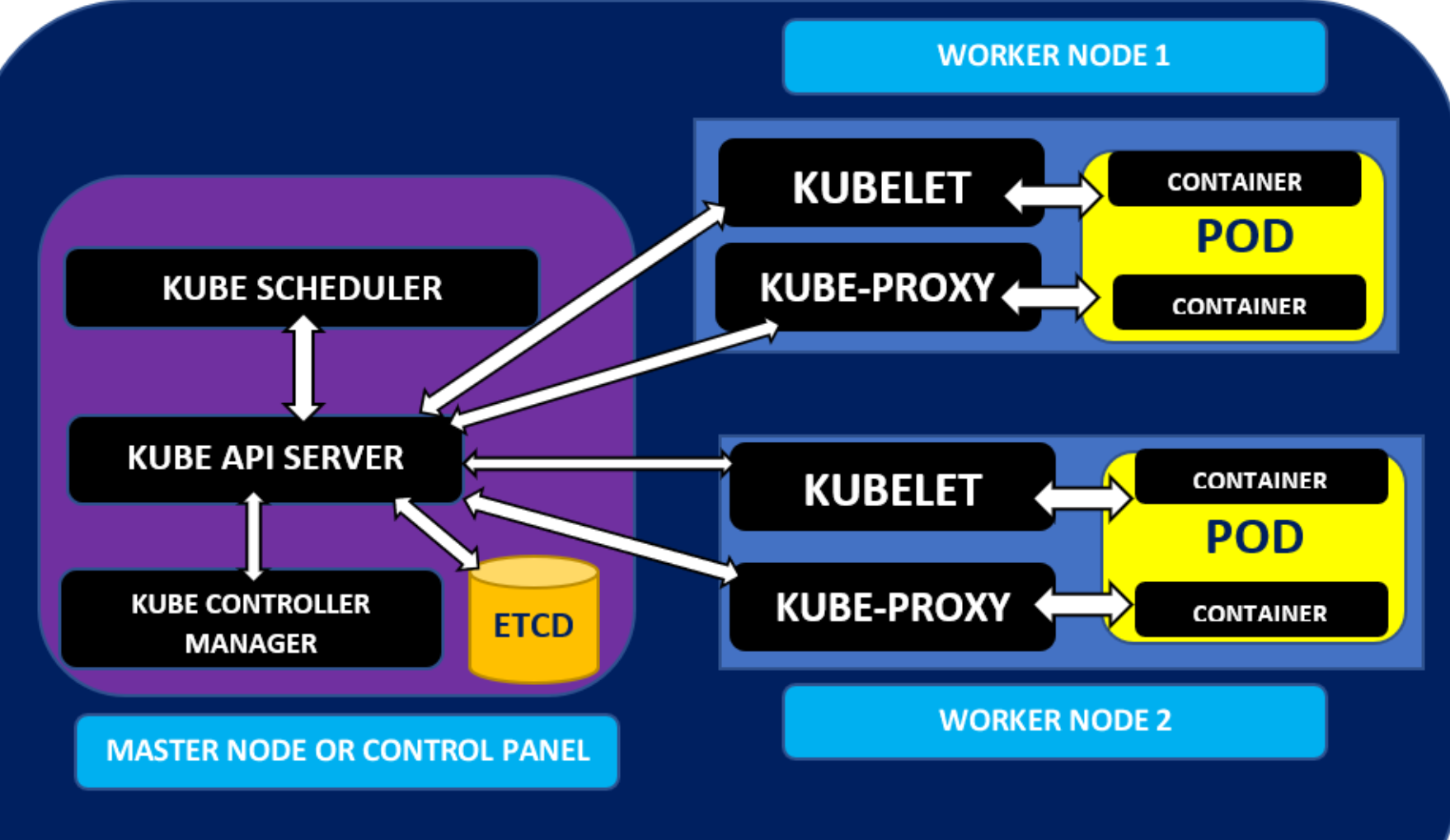
API server对外暴露了ComponentStatus接口,可以使用 kubectl get componentstatuses 查询。
k8s各个组件间只能通过API server进行通信,组件间不会直接通信。包括访问etcd也需要通过api server。 Control panel上的组件可以分散到多台服务器上,每个组件也可以运行多个实例保证高可用。其中etcd和api server可以多实例同时运行,scheduler和controller manager只能有一个实例在运行,其它实例待命。 Control panel上的组件以及kube-proxy可以直接部署在系统上,也可以作为pod来运行。kubelet是唯一一个以系统组件来运行的,由kubelet来运行pod。所以要把control panel作为pod来运行的话,需要把kubelet部署在master上。
etcd
- k8s 使用etcd来持久化信息,包括pod、replicaSet、service等等。只有api server可以和etcd通信。
- api server 使用乐观锁(OptimisticLock)控制对etcd数据的更新,每个对象上含有一个metadata.resourceVersion字段。
- 多个etcd使用 RAFT 一致性算法来达成一致。
- etcd实例应该是奇数。因为只有超过总数半数的实例在线才能达成共识,所以2个实例比1个实例更糟,挂掉的概率增加了一倍。比如4个节点,需要3个节点(超过4的半数2)在线。
乐观锁:取数据的时候都认为别人不会修改,不锁。更新数据的时候,先检查更新前的版本和自己之前读取的版本是否一致,一致则更新,否则重新读取。本质是CAS(Compare and Swap)。 悲观锁:很悲观,取数据的时候认为别人会修改,所以取数据要上锁。
api server
以restful api提供对集群状态的CRUD操作,数据保存在etcd中。api server会对客户端身份做认证、授权,校验数据对象,对更新提供乐观锁处理的功能。
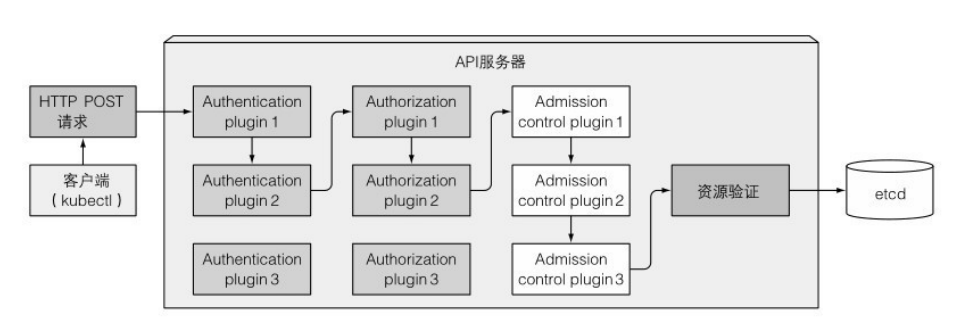
可以配置一个或者多个插件,来对操作进行认证、授权、准入控制。
资源变更的监控
客户端到api server来监听在etcd上配置的变更,有变更时api server会通知客户端。kubectl get po --watch就可以监听pod的变化。
Controller manager
工作流程:
- 调度器来决定pod运行在哪个节点,调度器连接api server并监听,等待创建新pod。
- 决定在某个节点上创建新pod,并更新api server上的pod定义。
- kubelet通过api server知道pod被调度到自己的节点,于是创建容器。
Controller manager里有多种controller,包括ReplicaSet、DaemonSet controller,node controller, service controller, persistent volume controller…这些控制器之间不会直接通信,都和api server通信。
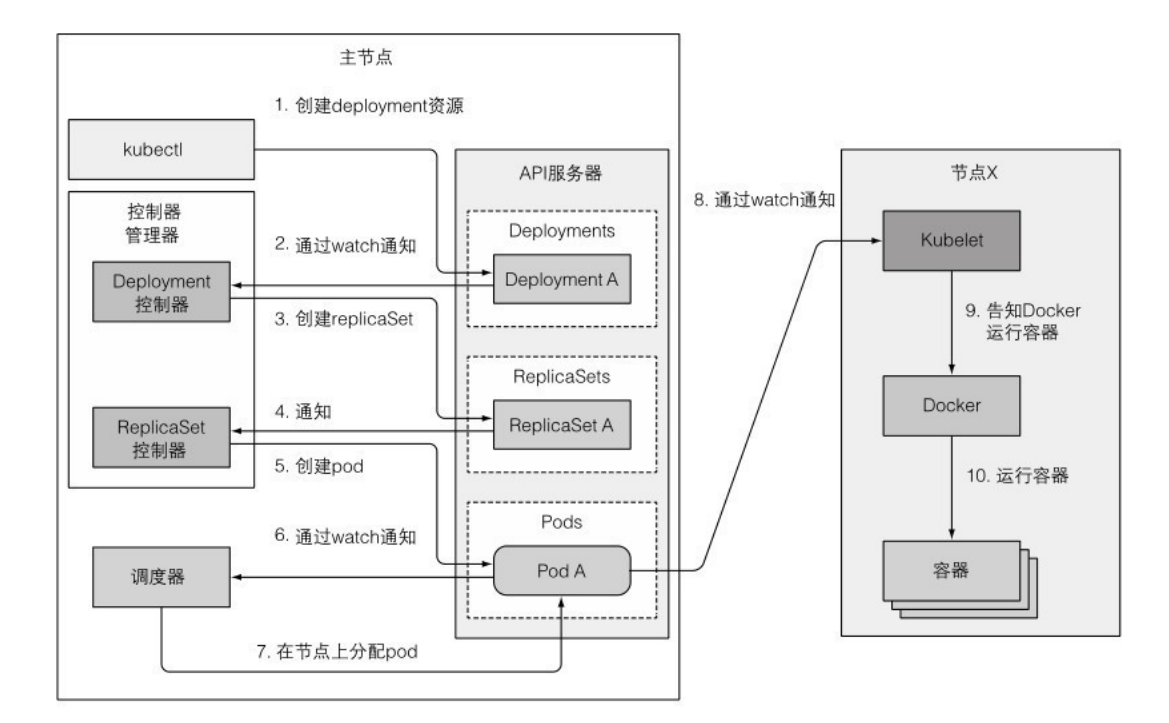
可以看出前面的操作都在controller panel中进行,可通过 kubectl get events --watch 查看事件。
Kubelet
工作流程:
- 连接api server创建一个node资源来注册本节点。
- watch api server是否给本节点分配pod,若分配则启动pod容器。
- 监控本地运行的容器,向api server报告它们的状态、事件和资源消耗。
- 容器出错时,重启容器
- pod从api server中删除时,kubelet终止容器,并通知api server该pod已被终止。
kubelet可以从api server获得需要运行的pod,也可以通过指定本地目录下的pod清单来运行pod。
pod内会多创建一个container来保证Linux命名空间不变
当pod运行时,首先会创建一个基础的container(COMMAND执行了pause),该容器通常和pod的生存周期相同,该容器的目的是确保这个pod运行后有一致的Linux namespace。因此,pod内有多个容器,或者容器在pod中被重启,也能保证他们有一致的命名空间。
kube-proxy
每个工作节点上除了有kubelet,还要运行kube-proxy。kube-proxy确保对service或者pod的访问都可以到达。
kube-proxy有两种代理模式:
- userspace proxy。客户端->iptables(kube-proxy配置iptables)->kube-proxy->pod。
- iptables proxy。客户端->iptables(kube-proxy配置iptables)->pod。这种模式,数据包不经过kube-proxy。
userspace proxy,对性能影响大,它以轮询模式选择pod做load balance。iptables proxy,随机选择pod。
kube-proxy使用iptables来转发数据包
- 监控 service 的创建
当创建service时,虚拟IP地址就会分配给service。之后API服务器会通知所有在节点上的kube-proxy客户端有个新服务已经被创建了。然后,每个kube-proxy都会让该服务在自己的节点上可寻址。原理是通过创建iptables规则,确保每个目标为service的IP/端口被修改为支持服务的pod上。
- 监控 Endpoint 对象
监控 Endpoint 来保证kube-proxy知道如何转发数据包到pod上。
control panel 中组件挂掉时的选举
选举时,这些组件不需要互相通信。领导者的选举方式是大家都尝试在api server创建一个endpoint对象,其中包含leader/holderIdentity字段指向自己,成功写入的就成为领导者。api server的乐观锁保证了并发只有一个会成功。
多control panel或多组件时,领导者负责更新资源。当领导者宕机,其它组件发现资源超时也没有更新,就尝试将自己写到api server中成为领导者。
k8s的安全防护
认证和授权
Authentication
pod使用ServiceAccount来表明自己的身份,一个ServiceAccount可以被多个pod使用。SA也是和Pod、ConfigMap等一样都是资源,每个namespace会有一个默认的ServiceAccount。
1
2
3
4
5
6
7
8
9
# 创建SA
kind: ServiceAccount
metadata:
name: mysa
# SA分配给pod
kind: Pod
spec:
serviceAccountName: mysa
Authorization
k8s里包括一些授权插件,包括RBAC,ABAC(基于属性的访问控制),WebHook插件等。
- RBAC中的Role和ClusterRole定义了可以在哪些资源上执行什么操作。
- RoleBinding 和 ClusterRoleBinding 将Role和ClusterRole绑定在用户、组和ServiceAccount。
命名空间ns
pod中的容器有自己的network ns, PID ns, IPC ns。
pod使用宿主节点的network ns
pod中的容器可直接看到和使用宿主节点的网络信息。
1
2
3
kind: Pod
spec:
hostNetwork: true
pod只绑定宿主节点的端口,而不用宿主节点的整个network ns
通过配置pod的spec.containers.ports字段中,某容器的hostPort属性来实现。这时,到达宿主节点该端口的连接会直接转发到pod的对应端口上。
1
2
3
4
5
6
7
# 可以通过pod IP的8080访问,也可以通过节点的9090访问。
kind: Pod
spec:
containers:
ports:
- containerPort: 8080
hostPort: 9090
注意和 Service 的 NodePort 的区别,NodePort会将连接转发到随机选取的pod上,不管pod是不是在本节点。 由于指定的端口会占用宿主机的端口,所以一个节点只能运行一个绑定某端口的pod,需要多个pod时,调度器会自动在其它节点上启动该pod,如果无多余的节点,则pod会pending。
pod使用宿主节点的PID和IPC ns
- pod spec.hostPID为true时,pod内的容器可以看到宿主的全部进程信息。
- pod spec.hostIPC为true时,pod内的容器可以使用IPC和宿主的进程通信。
1
2
3
4
kind: Pod
spec:
hostPID: true
hostIPC: true
security-context对pod容器进行更细粒度的控制
容器运行使用的用户可以在Dockerfile中通过USER来指定。如果没有指定,也没有配置security-context时,pod中的容器默认以root用户、root组运行。
指定用户运行容器
1
2
3
4
5
6
# runAsUser指定一个用户ID,不是用户名
kind: Pod
spec:
containers:
securityContext:
runAsUser: 405
指定非root用户运行容器
避免镜像被攻击后,运行恶意镜像,所以可以指定非root用户运行容器。
1
2
3
4
5
kind: Pod
spec:
containers:
securityContext:
runAsNonRoot: true
特权模式运行pod
pod此时可以在宿主机上做任何事情,比如kube-proxy就可以修改宿主机的iptables。特权模式的pod可以看到宿主机的/dev,所以也就可以访问到宿主机的所有设备。
1
2
3
4
5
kind: Pod
spec:
containers:
securityContext:
privileged: true
为容器指定可支持的内核功能
privileged=true 给pod的权限太大,可以指定个别的内核功能给pod。
1
2
3
4
5
6
7
8
9
10
# 该pod可以修改系统时间。需要把内核功能的 CAP_SYS_TIME 去掉 CAP_ 前缀。
# add 添加功能,drop 去掉默认有的功能,比如chown文件的权限。
kind: Pod
spec:
securityContext:
capabilities:
add:
- SYS_TIME
drop:
- CHOWN
阻止容器对自己的根文件系统进行写入操作
1
2
3
4
5
kind: Pod
spec:
containers:
securityContext:
readOnlyRootFilesystem: true
PodSecurityPolicy 进行集群级别的安全设置
PodSecurityPolicy 资源无命名空间,定义了能否在pod中使用某种安全相关的特性。PodSecurityPolicy插件需要安装才可使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 容器不允许使用宿主IPC、PID、Network namespace
# 容器只能使用10000-11000之间端口
# 容器不能在特权模式下允许
# 容器可以以任意用户、组运行
# 容器可以使用任何SELinux选项
kind: PodSecurityPolicy
spec:
hostIPC: false
hostPID: false
hostNetwork: false
hostPorts:
- min: 10000
max: 11000
privileged: false
readOnlyRootFilesystem: true
runAsUser:
rule: RunAsAny
fsGroup:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
seLinux:
rule: RunAsAny
pod的网络隔离
NetworkPolicy可以用标签选择器来匹配pod,或者用CIDR指定IP段,然后指定哪些ingress或者egress允许。
集群中的CNI或者网络方案需要支持NetworkPolicy。
在一个ns中启用网络隔离
默认情况下,pod可以被任意来源访问。可以启用对ns中所有pod的网络隔离,阻止所有访问。
1
2
3
4
# podSelector 的value为空,则匹配ns中的所有pod
kind: NetworkPolicy
spec:
podSelector:
对同一个ns中pod的访问
1
2
3
4
5
6
7
8
9
10
11
12
13
# 标签app=mydb的pod只允许标签app=myapp的pod,且只能访问3306端口。myapp可直接或通过Service访问到mydb。
kind: NetworkPolicy
spec:
podSelector:
matchLabels:
app: mydb
ingress:
- from:
- podSelector:
matchLabels:
app: myapp
ports
- port: 3306
不同ns中pod的访问
将上面的 podSelector 变成了 namespaceSelector 来选择指定的ns。
1
2
3
4
5
6
7
8
9
10
11
12
kind: NetworkPolicy
spec:
podSelector:
matchLabels:
app: mydb
ingress:
- from:
- namespaceSelector:
matchLabels:
tenant: xxx
ports
- port: 3306
限制pod的outbound流量
1
2
3
4
5
6
7
8
9
10
11
# pod aaa,只能访问pod bbb
kind: NetworkPolicy
spec:
podSelector:
matchLabels:
app: aaa
egress:
- to:
- podSelector:
matchLabels:
app: bbb
使用CIDR限制
1
2
3
4
5
# 指明了inbound rule,来自192.168.0.0/24
ingress:
- from:
- ipBlock:
cidr: 192.168.0.0/24
对资源的管理
创建pod时,可以指定其中容器对CPU和内存的最小要求(requests),以及最大限制(limits)。kubelet会向API server报告节点相关数据。
1
2
# 查看节点资源总量和已分配情况
kubectl describe nodes
为pod中的容器做资源分配
requests设置容器的最小的需求
requests的作用:
- 保证了该容器需要使用的最小资源。避免容器部署在资源不够的节点上。如果节点上可分配(注意不是可用)的资源小于requests的要求,则pod不会分配到该节点。比如已经有容器requests了80%的总CPU,哪怕实际只用了60%,也不会在该节点上部署requests 25%的pod。
- 当容器都全力使用CPU时,CPU用量会按照各个容器的requests的比例来分配。
1
2
3
4
5
6
7
8
9
10
# CPU指定为200毫核,即一个CPU core的1/5.
# memory申请100MB。
kind: pod
spec:
containers:
- image: test
resources:
requests:
cpu: 200m
memory: 100Mi
调度器在调度时,可根据参数设置优先级: LeastRequestedPriority,优先将pod调度到requests少的节点。 MostRequestedPriority,优先将pod调度到requests多的节点。可充分利用节点,释放不使用的节点以节省资金。
limits设置容器的最大使用量
CPU是可压缩的资源,某个容器占用CPU高了,我们可以限制它的CPU用量。 内存是不可压缩资源,如果进程申请了内存,除非主动释放,否则操作系统也不能让它主动释放内存(除非kill)。所以对内存进行限制,避免了单个pod故障导致整个节点不可用。
limits的特点:
- 与requests不同,limits不受节点可分配资源量的限制,也就是可以超卖。
- 对CPU的限制,仅仅会让该容器分配不到比限额更多的CPU资源。
- 当进程尝试申请比限额更多的内存时,会被OOM kill。k8s会尝试重启,如果继续失败,会增加下次重启的时间间隔,从20s一直几何倍数增加到300s。
- 当然如果节点资源总量超过100%,一些容器会被kill。
注意:在pod内的容器,看到的CPU和内存数量是节点的,并不是limits后的。所以应用不能根据查询到的CPU和内存无限的申请用量。
1
2
3
4
5
6
7
8
9
10
# CPU最大不能超过1 core
# 由于没有指定requests,所以requests将会设置为和limits相同的值。
kind: pod
spec:
containers:
- image: test
resources:
limits:
cpu: 1
memory: 100Mi
pod的QoS
由于limits设置的可以超卖,所以k8s有可能依据QoS选择pod kill掉。根据容器requests和limits的设置情况,将pod分为3个QoS等级:
- BestEffort(优先级最低):没有配置requests和limits的pod,当资源不够时,最先被kill。
- Guaranteed(优先级最高):pod中的每个容器都设置了requests和limits,并且他们的值相同。
- Burstable:除了前两种的其它pod。
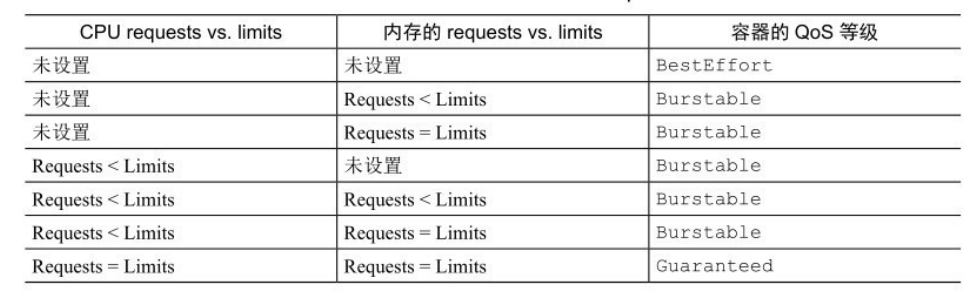
当容器的QoS等级相同时,根据OOM分值kill掉分值高的pod。比如A requests 100MB,B requests 200MB,A实际用量150MB,B实际用量280MB,A先被kill,因为A超过它requests的比例更高。
为命名空间的pod设置使用量
LimitRange
LimitRange设置ns中requests和limits的默认值,以及最大最小值。避免了需要为每个pod设置资源限制。只有在LimitRange范围内的pod,才可以在该ns中被创建。但LimitRange只影响apply后创建的pod,对已创建的pod不影响。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 可以设置Pod、container和PVC。
# maxLimitRequestRatio 指定request和limit的最大比例。
kind: LimitRange
spec:
limits:
- type: Pod
min:
cpu: 50m
memory: 100Mi
max:
cpu: 1
memory: 1Gi
- type: Containers
defaultRequest:
cpu: 100m
memory: 10Mi
default:
cpu: 500m
memory: 200Mi
min:
cpu: 50m
memory: 100Mi
max:
cpu: 1
memory: 1Gi
maxLimitRequestRatio:
cpu: 4
memory: 5
- type: PersistentVolumeClaim
min:
storage: 1Gi
max:
storage: 10Gi
ResourceQuota
ResourceQuota可限制ns中所有pod允许使用的CPU、内存、PVC总量,以及可创建的对象数量。使用kubectl describe quota查看配额使用情况。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# scopes设置quota的生效范围,比如BestEffort Qos的,以及没有有效期的pod上。
kind: ResourceQuota
spec:
scopes:
- BestEffort
- NotTerminating
hard:
requests.cpu: 500m
requests.memory: 100Mi
limits.cpu: 2
limits.memory: 500Mi
requests.storage: 1Ti
pods: 10
secrets: 20
persistentvolumeclaims: 5
services: 8
services.loadbalancers: 1
监控资源使用量
为了合理的设置requests和limits,需要监控pod的资源使用量。
收集、获取资源使用情况
kubelet中包含了一个 cAdvisor 的agent,会收集本节点和容器的资源消耗情况。可以在集群中运行一个 Heapster 组件来统计整个集群的监控信息。
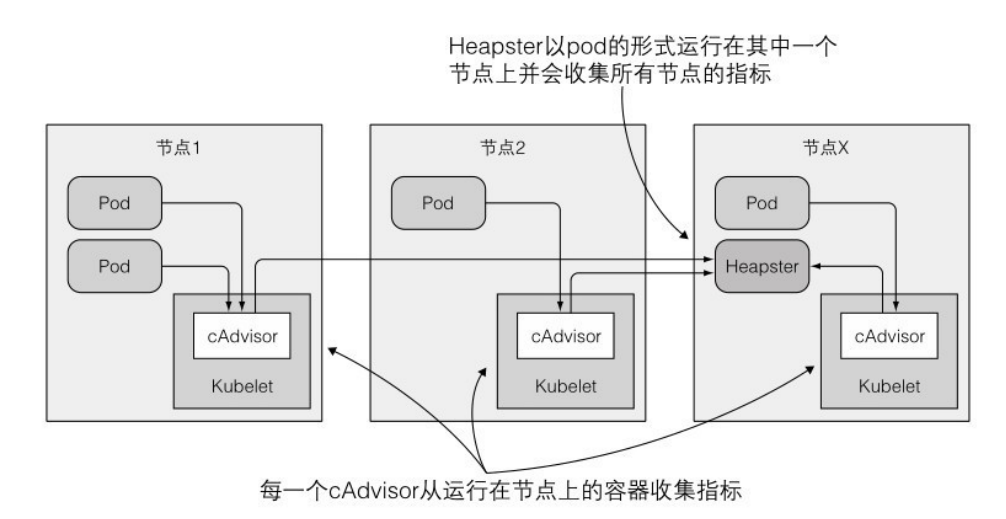
在Heapster运行了一会儿后,就可以通过下面的一些命令来获取信息:
1
2
3
4
5
6
7
8
# 节点CPU和内存实际使用量,注意kubectl describe node看的是节点CPU和内存的requests和limits
kubectl top node
# pod CPU和内存的实际使用量
kubectl top pod --all-namespaces
# minikube需要安装插件
minikube addons enable heapster
持续监控历史资源使用的统计信息
cAdvisor 和 Heapster 都只保存短时间内的数据,如果需要长时间的数据,可以用 InfluxDB 来储存数据,Grafana 对数据进行可视化和分析。
InfluxDB 和 Grafana 可以用docker方式运行。
pod和节点的自动伸缩
pod的横向自动伸缩 (scale out)
pod的横向auto scale由Horizontal controller执行,通过创建 HorizontalPodAutoscaler(HPA)来配置和启用。可基于CPU、内存、其它metrics来实现自动伸缩。
HPA流程
利用 cAdvisor 获取pod的信息,Heapster汇集,HPA从Heapster获取信息,计算后更新Deployment。
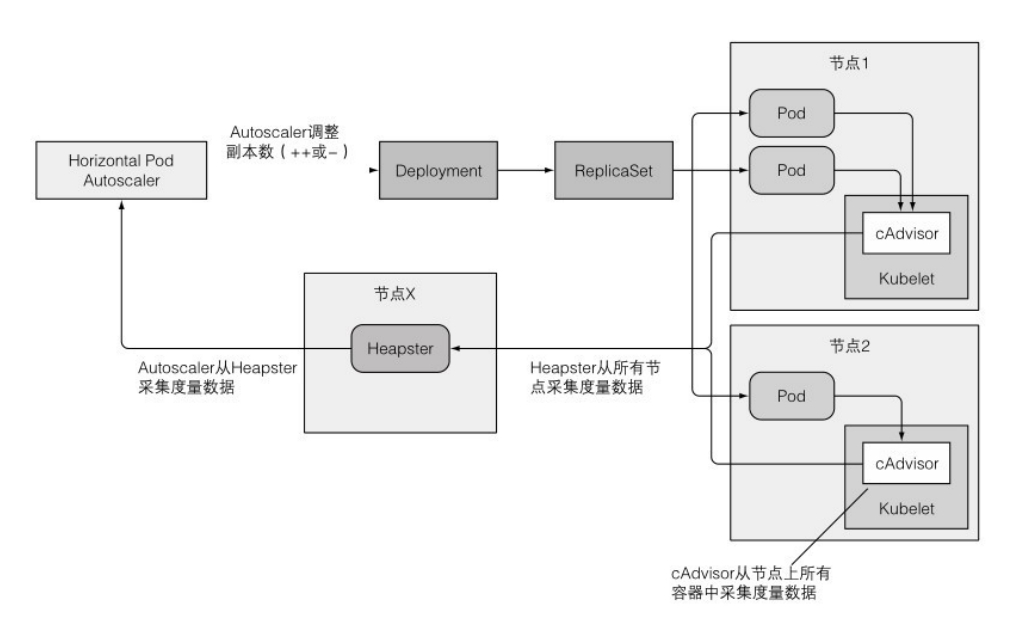
基于CPU使用率自动伸缩
要使用HPA,必须给pod设置CPU requests,这样HPA才能衡量CPU使用率。可以使用yaml定义资源,或者命令行直接修改。
HPA衡量的CPU使用率 = 容器的CPU实际使用率 / 设置的CPU requests
1
2
3
4
5
6
# autoscaler会调整副本的数量,使cpu使用率接近30%
kubectl autoscale deployment xxx --cpu-percent=50 --min=1 --max=5
# 查看HPA
kubectl get hpa
kubectl describe hpa
伸缩操作的速率限制:单次扩容操作最多让当前副本数翻倍。两次扩容间也有时间限制,比如3分钟内没有伸缩操作才会扩容,5分钟内没有伸缩操作才会缩容。
其它metrics
可基于每秒查询次数(QPS)、平均响应时间,等等进行自动缩放。
1
2
3
4
5
6
7
8
9
kind: HorizontalPodAutoscaler
spec:
maxReplicas: 5
minReplicas: 1
metrics:
- type: Pods
resource:
name: qps
targetAverageValue: 100
缩容到0副本?
目前HPA不支持缩容到0副本。也就是当没有请求的时候,缩容到0副本,有请求来时先被阻塞,直到pod启动,再转发请求到新pod上。未来k8s也许会支持。
pod纵向缩放和节点的横向伸缩
- pod纵向缩放,需查文档看k8s有没有实现,目前只能用替代方案。
- 节点的横向伸缩,需要云服务商的支持,目前GKE、GCE、Azure、AWS都支持节点的横向伸缩。
高级调度
Taints 和 Tolerations
节点可以表明自己的污染度(Taints),pod可以表明自己的容忍度(Tolerations),符合条件的pod才会被部署到节点上。节点选择器虽然也有这样的功能,但是Taints可以在不修改已有pod信息的前提下,通过修改节点信息,来拒绝pod在某些节点上的部署。
比如集群的主节点上设置了Taints,保证只有control panel pod可以部署在主节点上。
pod的污染容忍度可以指定对污染的效果:
- NoSchedule:0容忍,pod不会调度到有这些污染的节点上。
- PreferNoSchedule:是NoSchedule的宽松版本,尽量不调度到有这些污染的节点上,但如果没有别的节点,也会被调度上去。
- NoExecute:前两者只在调度期间起作用,NoExecute会把节点上正在运行的pod去除。
亲缘性affinity
节点亲缘性
虽然nodeSelector可以指定pod被调度到哪种节点上去,但是affinity更强大,可以指定pod对节点的硬性限制,或者偏好。
1
2
3
4
5
kind: pod
spec:
affinity:
nodeAffinity:
...
pod亲缘性
pod亲缘性可以把前端pod和后端pod部署的尽量靠近。可以使用 matchLabels 和 matchExpressions 来匹配。requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 部署的pod必须被调度到匹配的pod选择器的节点上。
kind: Deployment
spec:
replicas: 5
template:
...
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: ...
labelSelector:
matchLabels:
app: backend
pod非亲缘性
希望pod彼此远离的时候,就把 podAffinity 字段换成 podAntiAffinity。目的之一是避免在同一个节点上影响性能,之二是部署在不同节点满足高可用性的需求。
Best practice
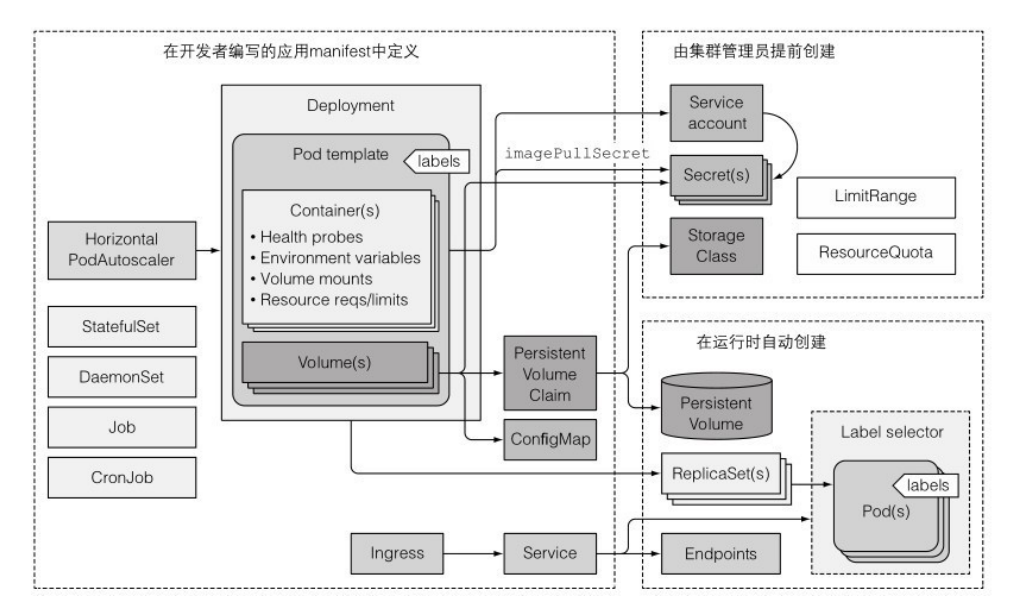
上图是一个典型的k8s应用环境:
- 提供服务的pod通过 service 来暴露自己。集群外访问时,可以将service配置为 LoadBalancer 或者 NodePort 类型的,也可以通过 Ingress 资源来开放服务。
- pod 模板通常会引用两种类型的Secret,一种用于从镜像仓库拉取镜像,另一种是pod中的进程使用的。Secret应由运维团队来配置,分配给 ServiceAccount,然后 SA 会被分配给pod。
- 一个应用也会包含一个或者多个 ConfigMap 对象,可以用 key value 来初始化环境变量,也可以在pod中以 configMap卷 来挂载。需要数据持久化的pod还需要 PVC卷。
- 一个应用可能会有 Jobs 和 CronJobs。DaemonSet通常由系统管理员创建,部署在各个节点上。
- 水平pod缩放(HorizontalPodAutoscaler)可由开发者或者运维团队配置。集群管理员可设置LimitRange和ResourceQuota,以控制每个pod和所有pod的资源使用情况。
- 资源通常会有多个标签,还应该有描述资源的注解,列出负责该资源的人员和团队的联系信息。
pod的生命周期
应用开发者的注意事项
由于pod可能被k8s杀死或者重新调度,所以应用开发者需要注意:
- 预料到本地IP和主机名会发生变化。如果要依赖主机名,必须使用StatefulSet。
- 预料到写入容器磁盘的数据会消失。即使pod没有重新建,但容器重建,也会创建新的writable layer。需持久化的数据需要保存在PV中。应用需注意PV中的数据损坏,导致容器不停崩溃。
控制pod的启动顺序
虽然在一个yaml文件中定义所有的pod,也是按顺序发给api server的,但无法保证哪个先启动。
控制启动顺序的方法:
- init容器:一个pod内可以包括多个init容器来完成初始化的工作,只有init容器运行结束后才会启动主容器。
- 使用 Readiness 探针检查依赖的pod。
1
2
3
4
5
6
7
8
9
# 使用initContainers来定义init容器。
spec:
initContainers:
- name: init
image: xxx
command:
- sh
- -c
- 'sleep 5;'
容器启动后(Post-start)和停止前(Pre-stop)的钩子
init容器是对应整个pod。此外可以在容器启动后和停止前添加钩子。
这里的钩子并不会在容器完全启动后才运行,而是和主进程并行执行。在钩子执行完毕之前,容器一直停留在Waiting状态,pod的状态会是Pending,而不是Running。如果钩子运行失败或者返回了非 0 的状态码,主容器会被kill。
1
2
3
4
5
6
7
8
9
10
11
12
# 使用postStart和preStop来定义
kind: pod
spec:
containers:
- image: xxx
lifecycle:
postStart:
exec:
command:
- sh
- -c
- "sleep 5;"
pod的终止
当kubelet意识到需要终止pod时,它开始终止pod中的每个容器。kubelet会给每个容器一定的时间来终止(Termination Grace Period),可在pod spec中的 spec.terminationGracePeriod 的Periods字段来为每个容器设置不同值,默认为30s。
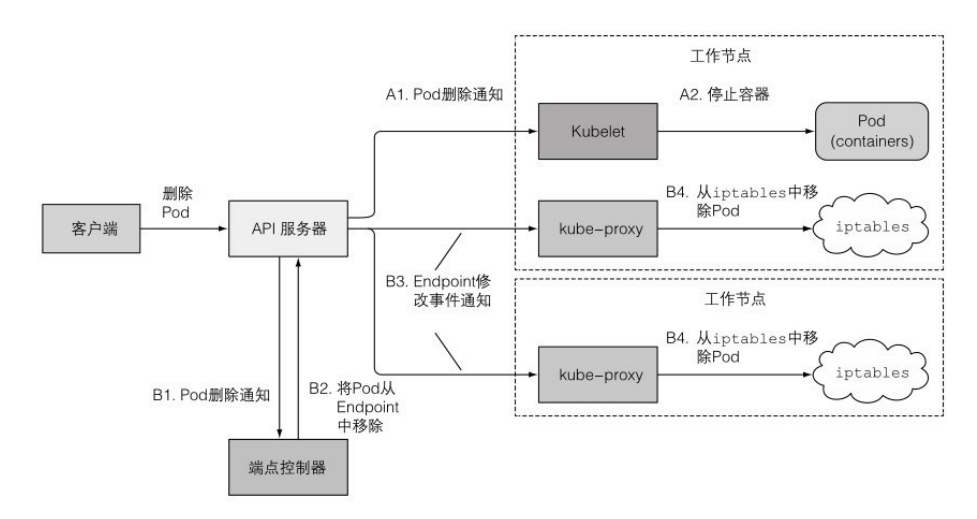
其中kubelet终止pod的流程:
- 如果有 PreStop,执行它,并等待执行完毕。
- 向容器主进程发送 SIGTERM 信号。
- 等待容器关闭或者等待终止期限超时。
- 如果容器没有主动关闭,使用 SIGKILL 强制终止进程。
注意容器收到 SIGTERM 时,并不意味着pod一定会被终止,有可能只是重启其中的容器。 kube-proxy很有可能收到的通知比kubelet收到的通知晚,导致容器已经停止服务了,之后kube-proxy才修改iptables,这样在中间的请求会收到access deny之类的错误。为了避免这样的问题,可以在容器的preStop里sleep几秒,这样iptables会先修改完,容器才会关闭。
让应用在k8s里方便运行和管理
- 衡量镜像最小化和方便使用的关系。只有可执行持续的镜像让第一次部署就很快,但是没有常用命令方便调试。
- 镜像尽量指定版本。用latest可能让版本不受控制,不同的pod运行了不同的版本。
- 给所有的资源都打上标签。标签可以包含:资源所属的应用名称,应用层级(前后端等),运行环境(开发、测试、预发布、生产),版本号,发布类型(稳定、canary、蓝绿等),租户等。
- 给资源加上注解。包括资源描述和负责人。
开发和测试的best practice
开发过程中在k8s之外运行应用
开发阶段,并不需要每次做完小的修改后都build docker,然后推送到registry,再deploy。
- 可以通过环境变量来连接后台的服务。
- 如果使用 ServiceAccount 来验证,可以把 SA 的secret文件用
kubectl cp复制到本地。或者在本地运行kubelet proxy。 - 开发过程中需要在容器内部运行时,可以把本地目录通过docker的volume挂载到容器中,这样应用有新的build时,重启容器就可以,不需要重新构建整个镜像。
使用minikube进行开发
可以将自己的shell指向minikube的docker-daemon。这样构建完镜像,不用再去推送镜像,它已存储在Minikube VM中,可直接使用该镜像。
1
eval $(minikube docker-env)
CI/CD
网上有很多资源,可以考虑 Fabric8 的项目。
k8s应用扩展
自定义资源 CustomResourceDefinition (CRD)
如果添加一个服务需要定义Deployment、Service、ConfigMap等,步骤很繁琐,对重复操作,可以使用 CRD。
1
2
3
4
5
6
7
# 定义CRD
kind: CustomResourceDefinition
spec:
scope: Namespaced
names:
kind: website
...
定义了CRD后,则可使用上面定义的website作为kind类型创建资源。
RedHat的Openshift
(内容待补充)
Helm
(内容待补充)
Centralized Logging (EFK)
EFK(Elasticsearch, Fluentd, Kibana)
- Elasticsearch: a period, distributed, and a scalable computer program that permits for full-text and structured search, further as analytics.
- Kibana: a robust knowledge visualization frontend, and dashboard for Elasticsearch.
- Fluentd: gather, transform, and ship logs knowledge to the Elasticsearch backend.
K8s tips
k8s修改资源的方式
- kubectl edit: 使用默认编辑器打开资源配置,资源对象会被更新。
kubectl edit deployment xxx - kubectl patch: 修改少量资源属性。
kubectl patch deployment xxx -p '{"spec" : ...}' - kubectl apply: 使用一个完整的yaml或json文件,来更新或创建对象,需要包含资源的完整定义。
kubectl apply -f xxx.yaml - kubectl replace: 将现有对象替换为yaml或json定义的新对象,只能用来更新,不能创建。
kubectl replace -f xxx.yaml - kubectl set image: 修改pod、ReplicationController、Deployment、DaemonSet、Job、ReplicaSet中的镜像。
kubectl set image deployment xxx container_name=aaa
Commands
命令行参数支持 tab 补全
1
2
3
yum install -y bash-completion
source <(kubectl completion bash)
source /etc/profile.d/bash_completion.sh
查看相关配置的帮助
1
kubectl explain replicaset.spec.replicas
在运行的容器中远程执行命令。双横杠 – 代表 kubectl 命令的结束,后面的内容会在 pod 内部执行。
1
kubectl exec pod_name -- ps -aux
在pod中运行command,和Docker很像
1
kubectl exec -it pod_name [-c container_name] -- bash
minikube 查询addons,启用组件
1
2
minikube addons list
minikube addons enable ingress
列出所有命名空间正在运行的 pod
1
kubectl get po --all-namespaces
修改资源
1
2
kubectl apply ...
kubectl edit ...
启动一个centos,并在后台等待
1
2
3
kubectl run centos --image=centos -- sleep infinity
kubectl exec centos -- ls
kubectl delete po centos
在本机和容器间相互传送文件
1
2
kubectl cp foo-pod:/container/aaa /local/aaa
kubectl cp foo-pod:/container/aaa /local/aaa -c container_name
Comments powered by Disqus.